
动态表单索引表读模型技术方案
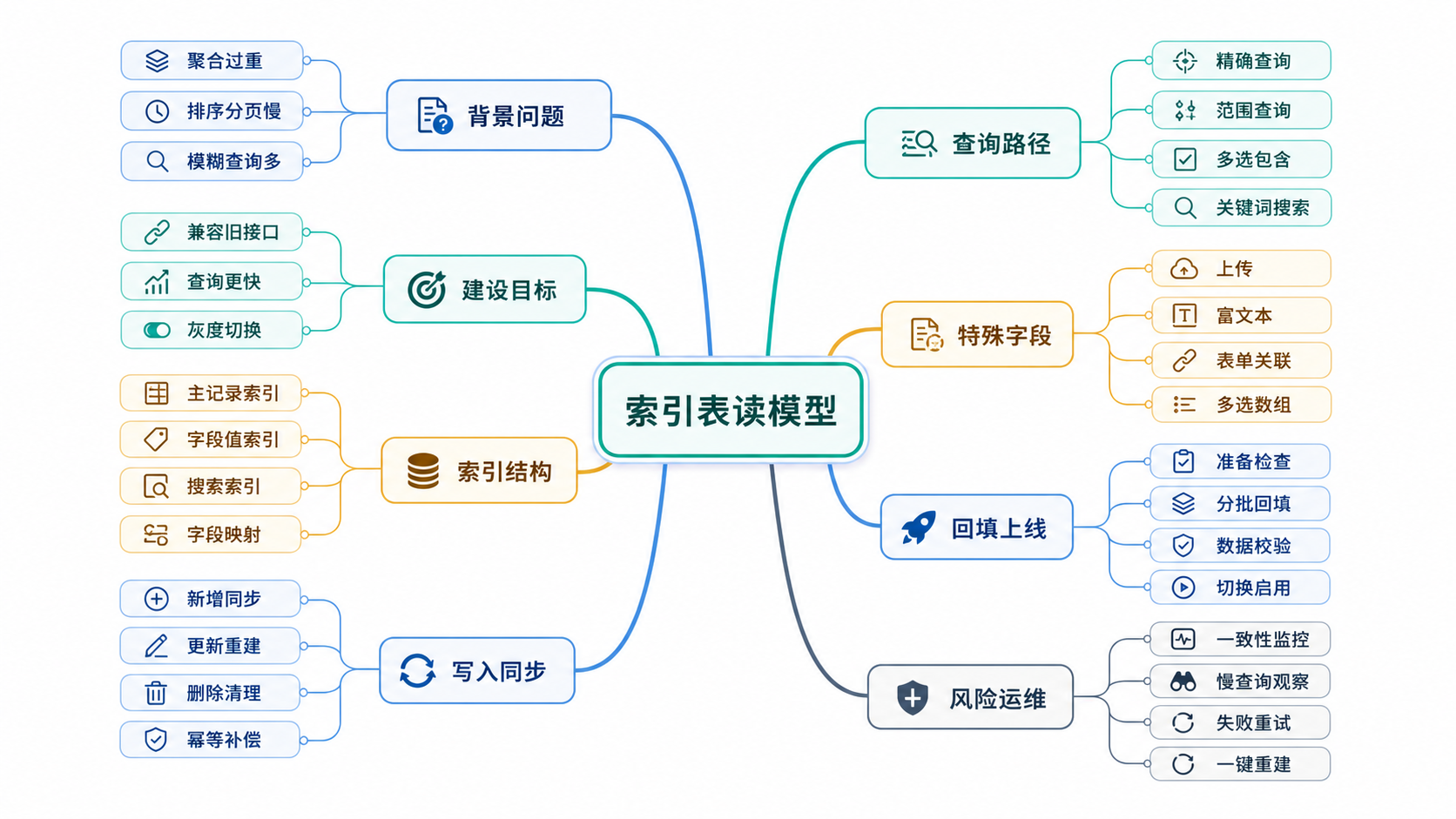
背景
动态表单系统通常会把字段值保存成 key-value 结构:一条主记录保存创建人、所属应用、创建时间、更新时间等固定字段,多条字段明细保存每个自定义字段的 key 和 value。这种结构的好处很明显,表单字段可以随时新增、删除、改名,写入模型也足够稳定,不需要因为每次字段调整就修改业务主表。
问题也会随数据量增长逐步显现。列表查询需要把多行字段值重新拼成一行,常见做法是通过条件聚合把字段转成列,再做筛选、排序、分页和统计。字段数量少、数据量小的时候还能接受;一旦某个表单有几十个字段、十万级主记录,查询就会变成大量明细行扫描、临时表、分组聚合和排序。尤其是 %关键词% 这种包含式模糊查询,本身就很难利用普通 B-Tree 索引,再叠加动态字段聚合,数据库压力会被放大。
索引表读模型的思路不是替换原来的存储方式,而是在原 key-value 表旁边维护一套面向查询的索引数据。旧表继续作为写入真源,保证字段灵活性和历史兼容;索引表只服务读取、筛选、排序、统计和搜索。这样做的好处是改造边界清楚,失败时可以随时退回旧查询,线上风险比直接改成物理宽表低很多。
目标
第一,降低列表查询的聚合成本。旧查询每次都要从字段明细表里把多行转成一行,索引表可以提前把查询常用信息拆成适合检索的结构,避免每次请求都重复做昂贵的转换。
第二,保持表单字段的动态能力。字段 key 可以新增、删除、改名,索引表通过字段永久标识和历史 key 映射来识别同一个字段,不要求每次字段变化都修改真实业务表结构。
第三,兼容原有返回结构。接口层对外仍返回原来的字段名和格式,前端、导入导出、审批、低代码面板等功能不需要感知底层查询路径变化。
第四,支持灰度开启。每个表单单独控制索引读模型状态,只有在准备、回填、校验都完成后才切换读取。状态异常时继续走旧查询,不能因为新读模型不完整影响线上业务。
第五,给 %关键词% 模糊查询留出专门通道。普通字段索引主要解决精确匹配、范围查询、排序和分页;包含式模糊查询需要单独的搜索索引或外部搜索引擎配合,不能指望一个通用 B-Tree 索引解决所有问题。
非目标
这套方案不改变原有 key-value 主存储,也不要求业务方马上迁移历史数据结构。它也不是为了让所有查询都变成毫秒级,特别是任意字段的长文本包含查询,如果没有全文索引、倒排索引或搜索引擎支持,仍然会有天然瓶颈。方案的重点是把最重的聚合、过滤、排序和统计从旧查询链路里拆出来,让系统有明确的性能上限和扩展路径。
总体设计
整体上分为三类索引表。
第一类是记录索引表,用来保存主记录维度的信息。每条表单数据对应一条索引记录,包含主记录 ID、表单 ID、创建人、用户、排序值、创建时间、更新时间、删除时间、同步版本、同步时间,以及一份用于兼容返回的 JSON 快照。它的作用是快速定位某个表单下的记录集合,并承担分页、统计和固定字段排序。
第二类是字段值索引表,用来保存每个自定义字段的可检索值。一条表单数据的多个字段会拆成多条索引行,每行包含表单 ID、主记录 ID、字段永久标识、当前字段 key、字段类型、值角色,以及字符串、数字、日期、时间、布尔、排序文本等多种规范化值。查询时根据字段类型选择合适的值列,避免把所有值都当字符串处理。
第三类是搜索索引表,用来处理包含式模糊查询和长文本搜索。它不追求替代字段值索引,而是专门保存适合搜索的文本内容,例如普通文本、富文本清洗后的纯文本、上传文件名、关联记录展示值、多选展示值等。后续可以先用数据库全文索引,数据量继续增长时再切到专业搜索引擎。
这三类表都可以按站点或租户分表,也可以先用统一表加分区键。选择哪种方式取决于数据隔离要求、单站点数据量、运维复杂度和数据库版本能力。实践上建议先保证查询条件里始终带上站点、表单和字段三个维度,再决定是否物理分表。
字段身份与 key 变化
动态表单里最容易被低估的问题是 key 会变。业务人员可能把字段从 phone 改成 contact_phone,也可能删除后新建一个同名字段。如果索引表只认 key,就会把历史数据和新字段混在一起,或者改名后查不到旧数据。
因此每个字段需要有一个稳定的字段永久标识。字段第一次创建时生成永久标识,后续修改 label、key、校验规则、展示配置时都沿用这个标识。字段映射表保存当前 key、历史 key、字段名称、字段类型、是否启用等信息。查询入口收到 key 后,先通过映射表解析到字段永久标识,再去索引表查值。这样 key 改名只影响映射,不需要全量改历史索引数据。
删除字段时不建议物理删除映射。更稳妥的做法是把字段标记为停用,列表默认不展示,但历史数据仍可在详情、审计或导出场景中按需要读取。真正清理索引数据可以放到离线归档任务里做,避免在线操作误删。
写入链路
新增表单数据时,旧 key-value 表仍然先写入。事务提交前或提交后,索引同步服务读取本次保存的字段值,构建记录索引、字段值索引和搜索索引。为了降低写入延迟,建议把同步分成两层:记录索引和关键字段索引可以同步写入,长文本搜索索引、富文本清洗、关联展示值补全可以异步补偿。
更新表单数据时,不能只同步本次传入的字段。很多快捷编辑或局部更新只提交一两个字段,如果直接覆盖索引快照,会把未提交字段清空。正确做法是先拿到当前完整字段值,再合并本次变化,然后重建这条数据的索引。对于字段值索引,可以先删除该记录旧索引,再插入新索引,逻辑简单且更容易保证一致性。
删除数据时,主记录软删除后,记录索引也标记删除时间,字段值索引和搜索索引可以同步删除或标记失效。列表查询默认排除已删除记录,回收站或审计查询可以按删除时间查询。
写入链路一定要有幂等能力。索引同步可以重复执行,不能因为重试导致重复数据。记录索引用主记录 ID 做唯一约束,字段值索引可以按主记录 ID 加字段永久标识批量重建,搜索索引也按同样方式覆盖。
查询链路
查询入口先读取表单配置和索引状态。只有状态为已启用时才走索引表;准备、回填、校验、失败、关闭状态都继续走旧查询。这样索引表可以在线回填,不影响用户操作。
精确筛选时,查询先到字段值索引表定位主记录 ID。比如某个字段等于指定值,就通过表单 ID、字段永久标识和值列查出匹配的主记录 ID,再回到记录索引表做分页和固定字段过滤。多个条件可以根据逻辑关系做交集或并集。条件较多时,优先选择区分度最高的条件作为起点,减少中间结果集。
范围查询按字段类型落到不同值列。数字字段走数字列,日期字段走日期或日期时间列,布尔字段走布尔列。不要把数字和日期都存在字符串列里再比较,否则排序和范围判断都会出现问题。
排序分两种。固定字段排序直接在记录索引表上完成,例如创建时间、更新时间、排序值。自定义字段排序可以先在字段值索引表按字段永久标识和值列排序,拿到主记录 ID 后再关联记录索引表补齐固定信息。中文排序要明确字符集和排序规则,不能依赖默认排序,否则不同数据库环境可能结果不一致。
分页和统计应尽量避免对子查询结果再做大范围排序。更稳的做法是先定位候选主记录,再用记录索引表完成分页。对于复杂筛选的 count,可以独立构造统计查询,不必复用列表字段投影,避免把展示用字段全部带入统计。
模糊查询处理
%关键词% 查询是这套方案里必须单独处理的重点。字段值索引可以改善精确匹配和范围查询,但对前后都有 % 的包含式查询帮助有限。继续在普通字符串列上做 LIKE '%xxx%',数据量大了仍会扫很多行。
短期可以把需要模糊查询的字段同步到搜索索引表,搜索索引表只保存可搜索内容和主记录 ID,至少避免先做 key-value 聚合。数据库支持全文索引时,可以对搜索内容建立全文索引;如果关键词包含中文,需要确认分词能力是否满足业务。如果数据库全文索引效果不稳定,建议把搜索能力抽成独立接口,后续接入搜索引擎时不影响主查询代码。
模糊查询还需要限制范围。用户在某一个表单里搜,搜索索引必须带表单 ID;在某个字段里搜,必须带字段永久标识;全字段搜索也要先限制表单和租户。不能把所有表单所有字段混在一起扫。
富文本字段要先清洗 HTML,只保留纯文本。上传字段可以索引文件名、扩展名、业务展示名,不建议索引完整外链。关联字段要索引展示值和关联记录 ID,多选字段可以按每个选项拆多行,也可以保存一份展示文本用于搜索。这里的原则是搜索内容面向用户输入,不照搬原始存储。
多选、富文本和关联字段
多选字段有两个查询需求:判断是否包含某个选项,以及按展示内容搜索。包含查询适合把每个选项拆成一行,值角色标记为数组项,并保留数组顺序。展示搜索则把选项标签拼成一份文本放入搜索索引。这样既能做精确包含,也能做关键字搜索。
富文本字段不适合直接进入普通字段值索引。它的原始内容可能很长,还带标签、样式和图片信息。建议记录索引里保留展示快照,搜索索引里保存清洗后的纯文本,字段值索引只保留必要的摘要或空值。列表排序通常不应允许富文本字段参与,除非业务有明确规则。
表单关联字段更特殊。它保存的可能是关联记录 ID,但用户看到的是关联记录的某个展示字段。索引同步时要同时保存 ID 和展示值。精确筛选按 ID 查,模糊搜索按展示值查。关联记录展示字段变更后,需要触发受影响数据的索引刷新,否则列表里会出现旧展示值。
上传字段也要拆开处理。原始值可以是文件 ID、路径或多个文件的组合。索引层不应该暴露真实存储域名或内部路径,只保存文件 ID、文件名、扩展名、数量、展示文本等必要信息。搜索文件名时走搜索索引,列表展示仍按原格式返回。
历史数据回填
历史回填是上线最关键的一步。对已有大量数据的表单,不能在用户点击开启时同步阻塞回填。建议采用“申请开启、准备表结构、分批回填、校验数量、灰度切换”的流程。
申请开启后,表单状态进入准备中,此时线上查询仍走旧链路,但新增和更新的数据可以开始维护索引。准备完成后,回填任务按主记录 ID 分批读取旧数据,每批构建索引并记录进度。任务可以暂停、重试、从断点继续,不能因为单条异常导致整个表单卡死。
回填完成后进入校验阶段。第一层校验是数量校验,确认源主记录和记录索引数量一致;第二层校验是抽样校验,随机抽取记录比较旧查询结果和索引查询结果;第三层校验是重点字段校验,对常用筛选字段检查空值、数字转换、日期转换、多选拆分等情况。校验通过后才把状态切为已启用。
如果校验失败,状态标记失败并记录原因。失败状态继续走旧查询,索引数据保留,方便修复后继续重建或补偿。不要失败就立即清空索引,否则排查成本会很高。
一致性与兜底
索引表是读模型,不是真源。任何时候发现索引不可用,都应该能退回旧查询。退回条件包括索引状态不是已启用、索引表不存在、字段映射缺失、查询构造异常、搜索服务超时等。兜底不是为了隐藏问题,而是为了保证业务不中断,同时把错误记录到日志和监控里。
一致性可以接受短暂延迟,但要有明确边界。新增和更新后的核心字段最好同步可见;长文本搜索和关联展示值可以允许异步延迟。对审批、支付、库存等强一致场景,不建议依赖异步索引结果做最终判断,仍应回到主存储校验。
索引和存储策略
记录索引表至少需要表单维度、主记录维度、创建时间、更新时间、删除时间、创建人、用户和排序值的组合索引。字段值索引表需要围绕表单 ID、字段永久标识、值列、主记录 ID 建索引,不同值类型分开建,避免一个大而全的复合索引拖慢写入。搜索索引表则根据所选搜索能力建立全文索引或外部索引映射。
索引不是越多越好。每多一个索引,写入和回填都会变慢,磁盘占用也会上升。建议先根据真实查询日志统计高频筛选字段和排序字段,只给高频路径加索引。低频字段可以走较慢路径,或者由运营配置为“可检索字段”后再建立索引。
对于超大表单,可以按表单或租户拆分索引表。拆分能降低单表数据量,也能减少索引膨胀,但会增加建表、回填、监控和清理的复杂度。是否拆分不应只凭感觉决定,应以单表数据量、写入频率、查询频率和运维能力为依据。
监控与运维
上线后需要关注四类指标。第一类是查询指标,包括索引查询耗时、旧查询耗时、慢查询数量、count 耗时、搜索耗时。第二类是同步指标,包括索引写入成功率、失败次数、重试次数、同步延迟。第三类是回填指标,包括回填进度、每批耗时、异常记录数、断点位置。第四类是状态指标,包括准备中、回填中、校验中、已启用、失败的表单数量。
运维工具上至少需要三个能力:手动重建某个表单索引、校验某个表单索引、对比某条记录的新旧查询结果。没有这些工具,问题发生后只能查库排查,效率会很低。
上线步骤
第一步,增加字段永久标识和字段映射能力,不切换查询。
第二步,增加索引表结构和同步服务,让新增、更新、删除可以维护索引,但默认不开启读取。
第三步,选择少量低风险表单做历史回填和校验,确认返回结构、筛选、排序、分页、导出都和旧查询一致。
第四步,对高数据量表单分批开启。每次只切少量表单,观察慢查询、错误日志和用户反馈。
第五步,把高频 %关键词% 查询接入搜索索引,并明确哪些字段支持模糊搜索,避免用户对所有字段做无边界搜索。
第六步,沉淀运维流程。包括回填失败怎么处理、字段改名怎么补偿、关联展示值变化怎么刷新、索引膨胀怎么归档。
示例 SQL
下面的 SQL 使用中性命名,只用于说明表结构和索引设计思路。生产环境实施时,需要结合实际数据库版本、字符集、分表策略、字段长度、归档策略和备份策略重新评审。
-- 字段映射表:保存字段永久标识和 key 的关系,解决字段改名、删除、重建带来的查询解释问题。
CREATE TABLE `dyn_form_field_map` (
`id` BIGINT UNSIGNED NOT NULL AUTO_INCREMENT,
`tenant_id` BIGINT UNSIGNED NOT NULL COMMENT '租户或站点标识',
`form_id` BIGINT UNSIGNED NOT NULL COMMENT '表单标识',
`field_uid` VARCHAR(64) NOT NULL COMMENT '字段永久标识',
`current_key` VARCHAR(128) NOT NULL COMMENT '当前字段key',
`old_keys` JSON NULL COMMENT '历史字段key列表',
`field_label` VARCHAR(128) NOT NULL DEFAULT '' COMMENT '字段显示名称',
`field_type` VARCHAR(64) NOT NULL DEFAULT '' COMMENT '字段类型',
`searchable` TINYINT(1) NOT NULL DEFAULT 0 COMMENT '是否进入搜索索引',
`sortable` TINYINT(1) NOT NULL DEFAULT 0 COMMENT '是否允许排序',
`enabled` TINYINT(1) NOT NULL DEFAULT 1 COMMENT '字段是否启用',
`created_time` DATETIME NULL COMMENT '创建时间',
`modified_time` DATETIME NULL COMMENT '修改时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_form_field_uid` (`tenant_id`, `form_id`, `field_uid`),
KEY `idx_form_current_key` (`tenant_id`, `form_id`, `current_key`),
KEY `idx_form_enabled` (`tenant_id`, `form_id`, `enabled`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='动态表单字段映射表';
-- 主记录索引表:一条表单数据对应一条记录索引,承担分页、固定字段过滤和兼容返回快照。
CREATE TABLE `dyn_form_record_idx` (
`id` BIGINT UNSIGNED NOT NULL AUTO_INCREMENT,
`tenant_id` BIGINT UNSIGNED NOT NULL COMMENT '租户或站点标识',
`form_id` BIGINT UNSIGNED NOT NULL COMMENT '表单标识',
`record_id` BIGINT UNSIGNED NOT NULL COMMENT '原始主记录标识',
`operator_id` BIGINT UNSIGNED NULL COMMENT '后台操作人标识',
`owner_ref` BIGINT UNSIGNED NULL COMMENT '业务归属对象标识',
`sort_value` INT NOT NULL DEFAULT 0 COMMENT '业务排序值',
`source_created_time` DATETIME NULL COMMENT '原始记录创建时间',
`source_modified_time` DATETIME NULL COMMENT '原始记录修改时间',
`source_deleted_time` DATETIME NULL COMMENT '原始记录删除时间',
`raw_snapshot` JSON NULL COMMENT '原始字段快照',
`display_snapshot` JSON NULL COMMENT '兼容接口返回的展示快照',
`sync_version` BIGINT UNSIGNED NOT NULL DEFAULT 1 COMMENT '同步版本',
`synced_time` DATETIME NULL COMMENT '同步时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_record` (`tenant_id`, `form_id`, `record_id`),
KEY `idx_form_record` (`tenant_id`, `form_id`, `record_id`),
KEY `idx_form_created` (`tenant_id`, `form_id`, `source_created_time`, `record_id`),
KEY `idx_form_modified` (`tenant_id`, `form_id`, `source_modified_time`, `record_id`),
KEY `idx_form_operator` (`tenant_id`, `form_id`, `operator_id`, `record_id`),
KEY `idx_form_owner` (`tenant_id`, `form_id`, `owner_ref`, `record_id`),
KEY `idx_form_sort` (`tenant_id`, `form_id`, `sort_value`, `record_id`),
KEY `idx_form_deleted` (`tenant_id`, `form_id`, `source_deleted_time`, `record_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='动态表单主记录索引表';
-- 字段值索引表:按字段拆行保存规范化值,支持精确查询、范围查询、多选包含和自定义字段排序。
CREATE TABLE `dyn_form_field_value_idx` (
`id` BIGINT UNSIGNED NOT NULL AUTO_INCREMENT,
`tenant_id` BIGINT UNSIGNED NOT NULL COMMENT '租户或站点标识',
`form_id` BIGINT UNSIGNED NOT NULL COMMENT '表单标识',
`record_id` BIGINT UNSIGNED NOT NULL COMMENT '原始主记录标识',
`field_uid` VARCHAR(64) NOT NULL COMMENT '字段永久标识',
`field_key` VARCHAR(128) NOT NULL COMMENT '写入索引时的字段key',
`field_type` VARCHAR(64) NOT NULL DEFAULT '' COMMENT '字段类型',
`value_role` VARCHAR(32) NOT NULL DEFAULT 'single' COMMENT '值角色:single、array_item、display等',
`value_string` VARCHAR(255) NULL COMMENT '短字符串值',
`value_text` TEXT NULL COMMENT '长文本值',
`value_number` DECIMAL(20, 6) NULL COMMENT '数字值',
`value_date` DATE NULL COMMENT '日期值',
`value_datetime` DATETIME NULL COMMENT '日期时间值',
`value_time` TIME NULL COMMENT '时间值',
`value_boolean` TINYINT NULL COMMENT '布尔值',
`value_sort_text` VARCHAR(255) NULL COMMENT '文本排序值',
`array_sort` INT NOT NULL DEFAULT 0 COMMENT '数组值顺序',
`synced_time` DATETIME NULL COMMENT '同步时间',
PRIMARY KEY (`id`),
KEY `idx_string` (`tenant_id`, `form_id`, `field_uid`, `value_string`, `record_id`),
KEY `idx_number` (`tenant_id`, `form_id`, `field_uid`, `value_number`, `record_id`),
KEY `idx_date` (`tenant_id`, `form_id`, `field_uid`, `value_date`, `record_id`),
KEY `idx_datetime` (`tenant_id`, `form_id`, `field_uid`, `value_datetime`, `record_id`),
KEY `idx_time` (`tenant_id`, `form_id`, `field_uid`, `value_time`, `record_id`),
KEY `idx_boolean` (`tenant_id`, `form_id`, `field_uid`, `value_boolean`, `record_id`),
KEY `idx_sort_text` (`tenant_id`, `form_id`, `field_uid`, `value_sort_text`, `record_id`),
KEY `idx_record_field` (`tenant_id`, `form_id`, `record_id`, `field_uid`),
KEY `idx_field_key` (`tenant_id`, `form_id`, `field_key`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='动态表单字段值索引表';
-- 搜索索引表:专门服务包含式模糊搜索和长文本搜索,不承担精确查询。
CREATE TABLE `dyn_form_search_idx` (
`id` BIGINT UNSIGNED NOT NULL AUTO_INCREMENT,
`tenant_id` BIGINT UNSIGNED NOT NULL COMMENT '租户或站点标识',
`form_id` BIGINT UNSIGNED NOT NULL COMMENT '表单标识',
`record_id` BIGINT UNSIGNED NOT NULL COMMENT '原始主记录标识',
`field_uid` VARCHAR(64) NOT NULL COMMENT '字段永久标识',
`field_key` VARCHAR(128) NOT NULL COMMENT '写入索引时的字段key',
`content` TEXT NOT NULL COMMENT '清洗后的搜索内容',
`synced_time` DATETIME NULL COMMENT '同步时间',
PRIMARY KEY (`id`),
KEY `idx_form_field_record` (`tenant_id`, `form_id`, `field_uid`, `record_id`),
KEY `idx_form_record` (`tenant_id`, `form_id`, `record_id`),
FULLTEXT KEY `ft_content` (`content`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='动态表单搜索索引表';
常见查询可以拆成两步:先从字段值索引或搜索索引定位记录 ID,再回到主记录索引表做分页和展示快照读取。
-- 示例一:自定义字段精确查询。
-- 查询某个表单下,指定字段等于某个字符串值的记录。
SELECT r.record_id, r.display_snapshot
FROM dyn_form_record_idx AS r
INNER JOIN dyn_form_field_value_idx AS v
ON v.tenant_id = r.tenant_id
AND v.form_id = r.form_id
AND v.record_id = r.record_id
WHERE r.tenant_id = :tenant_id
AND r.form_id = :form_id
AND r.source_deleted_time IS NULL
AND v.field_uid = :field_uid
AND v.value_string = :value
ORDER BY r.source_created_time DESC, r.record_id DESC
LIMIT :offset, :page_size;
-- 示例二:数字范围查询。
-- 查询指定字段处于某个数值范围内的记录。
SELECT r.record_id, r.display_snapshot
FROM dyn_form_record_idx AS r
INNER JOIN dyn_form_field_value_idx AS v
ON v.tenant_id = r.tenant_id
AND v.form_id = r.form_id
AND v.record_id = r.record_id
WHERE r.tenant_id = :tenant_id
AND r.form_id = :form_id
AND r.source_deleted_time IS NULL
AND v.field_uid = :field_uid
AND v.value_number BETWEEN :min_value AND :max_value
ORDER BY v.value_number ASC, r.record_id ASC
LIMIT :offset, :page_size;
-- 示例三:多选包含查询。
-- 多选字段按 array_item 拆行后,可以直接判断是否包含某个选项。
SELECT r.record_id, r.display_snapshot
FROM dyn_form_record_idx AS r
INNER JOIN dyn_form_field_value_idx AS v
ON v.tenant_id = r.tenant_id
AND v.form_id = r.form_id
AND v.record_id = r.record_id
WHERE r.tenant_id = :tenant_id
AND r.form_id = :form_id
AND r.source_deleted_time IS NULL
AND v.field_uid = :field_uid
AND v.value_role = 'array_item'
AND v.value_string = :option_value
ORDER BY r.source_created_time DESC, r.record_id DESC
LIMIT :offset, :page_size;
-- 示例四:包含式搜索。
-- 数据库全文索引是否适合中文,要结合实际分词能力验证;不满足时建议切到搜索引擎。
SELECT r.record_id, r.display_snapshot
FROM dyn_form_search_idx AS s
INNER JOIN dyn_form_record_idx AS r
ON r.tenant_id = s.tenant_id
AND r.form_id = s.form_id
AND r.record_id = s.record_id
WHERE s.tenant_id = :tenant_id
AND s.form_id = :form_id
AND r.source_deleted_time IS NULL
AND s.field_uid = :field_uid
AND MATCH(s.content) AGAINST (:keyword IN BOOLEAN MODE)
ORDER BY r.source_created_time DESC, r.record_id DESC
LIMIT :offset, :page_size;
如果数据库全文索引无法满足中文搜索,可以先保留同样的搜索索引表作为数据出口,再由异步任务同步到搜索引擎。接口层不要直接依赖某一种搜索实现,只需要表达“在哪个表单、哪个字段、搜索哪个关键词”。
示例代码
下面的代码是偏 PHP 风格的伪代码,目的是展示服务拆分和关键处理点。代码没有使用真实命名,也没有依赖具体项目结构。
<?php
class FieldValueNormalizer
{
/**
* 把原始字段值转换成索引表需要的规范化结构。
* 不同字段类型写入不同值列,避免查询时全部按字符串比较。
*/
public function normalize(array $field, $rawValue): array
{
$type = $field['field_type'] ?? 'text';
$base = [
'field_uid' => $field['field_uid'],
'field_key' => $field['current_key'],
'field_type' => $type,
'value_role' => 'single',
'value_string' => null,
'value_text' => null,
'value_number' => null,
'value_date' => null,
'value_datetime' => null,
'value_time' => null,
'value_boolean' => null,
'value_sort_text' => null,
'array_sort' => 0,
];
if ($rawValue === null || $rawValue === '') {
return [$base];
}
if ($type === 'number' || $type === 'amount') {
$base['value_number'] = is_numeric($rawValue) ? (float) $rawValue : null;
return [$base];
}
if ($type === 'date') {
$base['value_date'] = $this->formatDate($rawValue);
return [$base];
}
if ($type === 'datetime') {
$base['value_datetime'] = $this->formatDateTime($rawValue);
return [$base];
}
if ($type === 'boolean') {
$base['value_boolean'] = $rawValue ? 1 : 0;
return [$base];
}
if ($type === 'multi_select') {
return $this->normalizeArrayValue($base, (array) $rawValue);
}
$text = trim((string) $rawValue);
$base['value_string'] = mb_substr($text, 0, 255);
$base['value_text'] = $text;
$base['value_sort_text'] = mb_substr($text, 0, 255);
return [$base];
}
/**
* 多选字段拆成多行,既支持包含查询,也保留数组顺序。
*/
private function normalizeArrayValue(array $base, array $values): array
{
$rows = [];
foreach (array_values($values) as $index => $value) {
$row = $base;
$row['value_role'] = 'array_item';
$row['value_string'] = mb_substr((string) $value, 0, 255);
$row['value_sort_text'] = mb_substr((string) $value, 0, 255);
$row['array_sort'] = $index + 1;
$rows[] = $row;
}
return $rows ?: [$base];
}
/**
* 日期格式化失败时返回空值,避免错误数据污染范围查询。
*/
private function formatDate($value): ?string
{
$timestamp = strtotime((string) $value);
return $timestamp ? date('Y-m-d', $timestamp) : null;
}
/**
* 日期时间格式化失败时返回空值,异常记录交给校验任务发现。
*/
private function formatDateTime($value): ?string
{
$timestamp = strtotime((string) $value);
return $timestamp ? date('Y-m-d H:i:s', $timestamp) : null;
}
}
class FormIndexSyncService
{
private FieldValueNormalizer $normalizer;
public function __construct(FieldValueNormalizer $normalizer)
{
$this->normalizer = $normalizer;
}
/**
* 同步单条表单记录。
* 原始 key-value 表仍是真源,索引表只承担查询加速。
*/
public function syncRecord(array $record, array $fields, array $values): void
{
$now = date('Y-m-d H:i:s');
$recordIndex = [
'tenant_id' => $record['tenant_id'],
'form_id' => $record['form_id'],
'record_id' => $record['record_id'],
'operator_id' => $record['operator_id'] ?? null,
'owner_ref' => $record['owner_ref'] ?? null,
'sort_value' => $record['sort_value'] ?? 0,
'source_created_time' => $record['source_created_time'] ?? null,
'source_modified_time' => $record['source_modified_time'] ?? null,
'source_deleted_time' => $record['source_deleted_time'] ?? null,
'raw_snapshot' => json_encode($values, JSON_UNESCAPED_UNICODE),
'display_snapshot' => json_encode($this->buildDisplaySnapshot($fields, $values), JSON_UNESCAPED_UNICODE),
'sync_version' => time(),
'synced_time' => $now,
];
// 主记录索引用 record_id 做幂等覆盖。
$this->upsertRecordIndex($recordIndex);
// 字段值索引采用先删后插,避免局部更新后残留旧字段值。
$this->deleteFieldValueIndex($record['tenant_id'], $record['form_id'], $record['record_id']);
$this->deleteSearchIndex($record['tenant_id'], $record['form_id'], $record['record_id']);
foreach ($fields as $field) {
$key = $field['current_key'];
$rawValue = $values[$key] ?? null;
foreach ($this->normalizer->normalize($field, $rawValue) as $valueIndex) {
$this->insertFieldValueIndex(array_merge($valueIndex, [
'tenant_id' => $record['tenant_id'],
'form_id' => $record['form_id'],
'record_id' => $record['record_id'],
'synced_time' => $now,
]));
}
if (!empty($field['searchable'])) {
$content = $this->buildSearchContent($field, $rawValue);
if ($content !== '') {
$this->insertSearchIndex([
'tenant_id' => $record['tenant_id'],
'form_id' => $record['form_id'],
'record_id' => $record['record_id'],
'field_uid' => $field['field_uid'],
'field_key' => $field['current_key'],
'content' => $content,
'synced_time' => $now,
]);
}
}
}
}
/**
* 构建兼容旧接口的展示快照,接口层可以直接复用原返回结构。
*/
private function buildDisplaySnapshot(array $fields, array $values): array
{
$snapshot = [];
foreach ($fields as $field) {
$key = $field['current_key'];
$snapshot[$key] = $values[$key] ?? null;
}
return $snapshot;
}
/**
* 构建搜索内容,富文本、上传、关联字段都应在这里转成用户可搜索的文本。
*/
private function buildSearchContent(array $field, $rawValue): string
{
if ($rawValue === null || $rawValue === '') {
return '';
}
if (($field['field_type'] ?? '') === 'rich_text') {
return trim(strip_tags((string) $rawValue));
}
if (is_array($rawValue)) {
return trim(implode(' ', array_map('strval', $rawValue)));
}
return trim((string) $rawValue);
}
private function upsertRecordIndex(array $row): void
{
// 示例方法:生产环境用框架或数据库驱动提供的 upsert 能力实现。
}
private function deleteFieldValueIndex(int $tenantId, int $formId, int $recordId): void
{
// 示例方法:按租户、表单、记录删除旧字段值索引。
}
private function deleteSearchIndex(int $tenantId, int $formId, int $recordId): void
{
// 示例方法:按租户、表单、记录删除旧搜索索引。
}
private function insertFieldValueIndex(array $row): void
{
// 示例方法:插入新的字段值索引行。
}
private function insertSearchIndex(array $row): void
{
// 示例方法:插入新的搜索索引行。
}
}
查询服务可以把用户传入的 key 先解析成字段永久标识,再决定使用字段值索引还是搜索索引。
<?php
class FormIndexQueryService
{
/**
* 构建查询条件。
* 入参里的 field_key 不能直接查索引表,必须先解析成 field_uid。
*/
public function buildConditions(array $filters, array $fieldMaps): array
{
$conditions = [];
foreach ($filters as $filter) {
$fieldMap = $fieldMaps[$filter['field_key']] ?? null;
if (!$fieldMap || empty($fieldMap['enabled'])) {
continue;
}
$conditions[] = [
'field_uid' => $fieldMap['field_uid'],
'field_type' => $fieldMap['field_type'],
'operator' => $filter['operator'],
'value' => $filter['value'],
'use_search' => $this->shouldUseSearch($filter),
];
}
return $conditions;
}
/**
* 包含式模糊查询走搜索索引,精确和范围查询走字段值索引。
*/
private function shouldUseSearch(array $filter): bool
{
return ($filter['operator'] ?? '') === 'contains';
}
/**
* 根据字段类型选择值列,避免数字和日期按字符串比较。
*/
public function valueColumnFor(string $fieldType): string
{
if (in_array($fieldType, ['number', 'amount'], true)) {
return 'value_number';
}
if ($fieldType === 'date') {
return 'value_date';
}
if ($fieldType === 'datetime') {
return 'value_datetime';
}
if ($fieldType === 'boolean') {
return 'value_boolean';
}
return 'value_string';
}
}
风险点
最大的风险不是索引表建不出来,而是新旧查询结果不一致。原因可能来自字段格式化、空值处理、多选顺序、富文本清洗、关联字段展示值、数字和字符串比较差异。上线前必须准备对比工具,不能只看数量一致。
第二个风险是模糊查询预期过高。索引表能减少聚合成本,但无法让所有 %关键词% 查询天然变快。如果业务大量依赖包含式搜索,需要把搜索索引作为正式能力设计,而不是当成字段值索引的附属功能。
第三个风险是写入链路变重。索引同步越复杂,写入失败和延迟的概率越高。同步策略要区分核心索引和非核心索引,不要把所有清洗、补全、搜索处理都塞进用户请求事务里。
第四个风险是字段生命周期处理不完整。key 改名、字段删除、字段重建、字段类型变化都会影响索引解释。如果没有字段永久标识和映射表,后期维护会非常痛苦。
结论
索引表方案适合长期维护的动态表单系统。它保留 key-value 的灵活性,又把读取压力从运行时聚合转移到写入和异步同步阶段。相比每个表单一张物理宽表,它对字段变化更友好,破坏性更小;相比完全沿用旧查询,它能给筛选、排序、分页和搜索提供更清晰的优化空间。
这套方案的核心不是多建几张表,而是把“写入真源”和“查询读模型”分开管理。只要状态控制、历史回填、结果校验、搜索边界和兜底机制做完整,就可以在不改变外部接口结构的前提下,逐步缓解动态字段查询的性能瓶颈。














请先 登录后发表评论 ~